

引言:信息检索与信息组织的基本问题
信息检索的核心任务是从大规模数据集合中识别并返回符合用户信息需求的相关数据。这一过程的有效性从根本上依赖于前期的信息组织工作,其中标引是关键环节。标引是指对信息资源的内容特征进行系统化分析与标识,从而建立可供检索的索引数据库的过程。在信息科学领域,分类标引与自然语言标引构成了两种具有不同哲学基础与技术路径的核心标引范式。本文旨在系统阐述这两种标引方法的基本原理、技术实现、在信息检索系统中的应用及其发展趋势。
一、信息检索的复杂性挑战与标引的功能定位
信息检索系统面临的核心困难在于用户查询表述与文档内容表征之间的多重不对应关系。这主要包括:
语义不对应:简短的查询式难以完整表达复杂的信息需求,而文档则包含详尽但可能结构松散的内容。
词汇不对应:同一概念存在多种词汇表达形式(同义词),同一词汇也可能指代不同概念(多义词)。
规模不对应:待检索集合的规模使得线性的全文顺序匹配在计算效率上不可行。
标引的功能正是为了在上述不对应关系中建立有效的映射机制。通过对文档内容进行压缩、提炼和规范化表示,生成一套系统的检索标识(索引项),标引构建了原始文档集合的一个高效替代表示。检索操作在此索引上进行,从而实现对查询的快速响应。因此,标引的质量直接决定了信息检索系统的查全率与查准率性能。
二、分类标引:基于受控知识体系的标引方法
1. 理论基础与定义
分类标引是一种受控标引方法。它依据一个预先建立、结构固定的知识分类体系,将信息资源归入该体系中的一个或多个恰当类目。该分类体系通常采用层级结构,通过类号、类目名称及清晰的等级关系,展现学科或知识领域之间的内在逻辑联系。
2. 技术实现与过程
分类工具:依赖于权威的、标准化的分类法,如《中国图书馆分类法》(CLC)、《杜威十进分类法》(DDC)或专业领域分类表(如档案分类法等)。
标引过程:标引员(或自动分类系统)对文档进行主题分析,判断其主要论述的学科或主题范畴,然后根据分类法的规则,赋予其相应的分类号。
自动化发展:现代信息处理技术已实现一定程度的自动分类标引,主要采用机器学习方法(如朴素贝叶斯、支持向量机、深度神经网络),通过对已标引训练集的学习,构建分类模型,自动对新文档进行类别预测。
3. 在信息检索系统中的应用价值
系统性浏览与检索:为用户提供按学科知识脉络进行探索的路径,支持“族性检索”,便于发现某一宽泛主题下的所有相关资料。
检索结果的组织与导航:在返回大量检索结果后,可按分类号对结果进行聚类与排序,提升结果集的结构化程度与可理解性。
跨语言与跨库检索的中间语言:分类号作为一种独立于自然语言的符号系统,可作为中介,关联不同语言或不同数据库中论述同一主题的文献。
专业领域数据库的构建基石:在科学、法律、专利等专业领域,严格的分类标引是保证数据库专业性与检索效能的必要前提。
三、自然语言标引:基于词汇与统计特征的标引方法
1. 理论基础与定义
自然语言标引直接采用文献本身或标引过程中提取的自然语言词汇(单词、短语)作为索引项。它不依赖于外部受控词表,而是致力于捕捉文档内容在词汇使用上的统计特征与语义特征,其标引词汇与作者及用户的自然表达方式更为接近。
2. 技术实现层次
基于词汇的标引:早期的关键词标引,从标题、摘要或全文中抽取具有实质意义的词汇。
(1)基于统计模型的标引:
TF-IDF模型:TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency),通过TF与IDF的乘积评估词汇对文档的区分能力,是信息检索与文本挖掘的基础权重算法。
主题模型:如潜在狄利克雷分布模型(LDA),将文档视为若干潜在主题的概率混合,每个主题则表现为一系列相关词汇的概率分布,从而实现超越词汇表面的主题层次标引。
(2)基于深度语义表示的标引:
词嵌入与分布式表示:如Word2Vec、GloVe模型,将词汇映射为低维稠密向量,使得语义相近的词汇在向量空间中距离接近。
预训练语言模型:如BERT、RoBERTa等,通过在大规模语料上进行预训练,获得能够深刻理解上下文语境的双向语言表征能力。基于此类模型,可以生成文档或句子的语义向量,或直接识别出文档中的关键实体与关系,实现深度的语义标引。
3. 在信息检索系统中的应用价值
互联网搜索引擎的基础:支撑Google、Bing等通用搜索引擎对海量网页内容进行全文索引和相关性排序。
支持精确的特定事实检索:对于包含具体名称、数据、技术术语的查询,基于词汇匹配和语义相似度的自然语言标引具有直接优势。
实现语义检索与查询扩展:利用词向量或语言模型,可以计算查询与文档在语义空间中的相似度,并能自动将查询扩展为语义相近的词汇,缓解词汇不对应问题。
动态适应新词汇与新概念:无需像分类法那样等待官方修订,能够及时捕捉并索引新兴领域产生的术语和新概念。
四、方法比较与融合应用
1. 系统性比较
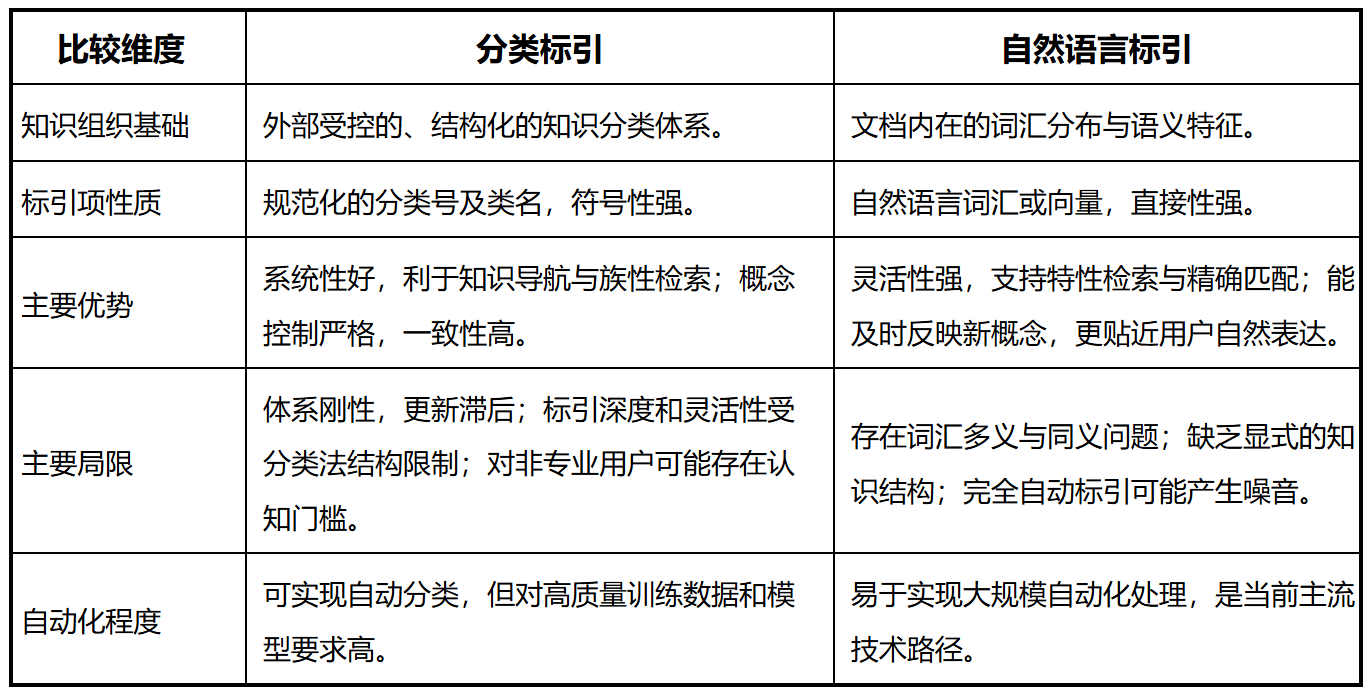
2. 协同融合模式
在实际的信息检索系统中,两者常协同工作以发挥综合优势:
混合检索界面:系统同时提供基于分类体系的浏览导航和基于关键词的自然语言搜索框。
分层过滤机制:用户先用自然语言查询获得初步结果集,再利用分类法提供的类别对结果进行二次精炼。
标引过程的互补:利用自然语言处理技术对文档进行深度分析,辅助或自动完成其在复杂分类体系中的归类(自动分类)。同时,分类体系的结构信息也可用于优化自然语言处理模型的主题识别能力。
知识图谱作为新型桥梁:知识图谱以结构化的方式表示实体、概念及其间关系,它既能整合分类法的层级结构,又能融合海量的实体同义词与属性信息,为下一代智能标引与检索提供统一的语义基础。
五、发展趋势与未来展望
当前,信息标引领域在人工智能技术的推动下呈现以下发展趋势:
深度语义标引的普及:基于预训练大语言模型(LLM)的深度语义理解能力,标引正从传统的词汇或主题层面,深入到对文档论点、方法、结论等细粒度知识单元的识别与关联。
自动化与智能化水平持续提升:自动分类、关键词自动抽取、摘要生成、元数据自动标注等技术将更加成熟、精准,降低人工标引成本,提升标引一致性。
个性化与情境化标引:标引系统将能够结合用户画像、检索历史及具体任务场景,动态调整标引的侧重点与呈现方式,提供更具个性化的信息组织与检索体验。
多模态信息标引:对于图像、音频、视频等非文本资源,结合计算机视觉、语音识别与自然语言处理技术,实现跨模态内容的统一语义标引与检索。
结论
分类标引与自然语言标引是信息组织领域应对信息检索需求的两大方法论体系。前者以规范化和结构化为核心,构建了稳定、系统的知识访问框架;后者以灵活性和直接性为特点,适应了信息快速增长与用户自然表达的复杂性。二者并非替代关系,而是在不同场景下各具效能,并随着技术的发展走向更深层次的融合。理解其原理、比较及应用,对于设计高效的信息检索系统、开发新型的知识服务,以及应对未来更加复杂多元的信息环境具有重要的理论意义与实践价值。信息标引技术的持续演进,始终围绕着如何更精确、更高效地建立用户信息需求与海量信息资源之间的有效连接这一核心目标。
撰稿人:赵萌萌
审核人:张梅华
